









前言
过去,很多在线智能客服经常被人吐槽为人工智障,随着ChatGPT等生成式大语言模型的兴起,我们有更简单的方案来实现一个更智能的在线客服。ChatGPT的通识问答能力很强,但落地到企业领域知识的时候,就容易胡说八道。
本文将为你详细介绍如何利用YCloud和OpenAI的相关接口能力,开发一个懂你业务的WhatsApp智能客服。(以YCloud为例)
YCloud是一家提供全球云通信的CPaaS服务公司,主要提供全球短信、邮件、语音验证码和WhatsApps等商业消息服务,并基于这些基础通信能力开发了Verify验证服务、Campaign多渠道消息营销服务、Contact CDP服务、Inbox WhatsApp客服坐席服务、Growth Tools营销增长工具等。2022年,YCloud和Meta官方达成合作,成为WhatsApp Business Platform在大中华区的首批解决方案提供商(WhatsApp BSP)。通过YCloud在线平台可以创建WhatsApp Business API账户,并获取WhatsApp Business API能力。YCloud通过整合WhatsApp Business API的能力,开发出了客服坐席Inbox平台,通过Inbox可以轻松对接WhatsApp商业账号和客服坐席,让一个账号可以服务成千上万的终端用户。
ChatGPT是OpenAI训练的大语言模型智能机器人,拥有较大的模型参数和语言预测能力。OpenAI也开放了和ChatGPT(3.5)底层能力一致的gpt-3.5-turbo 和 gpt-4模型能力接口,可以方便企业通过API调用的方式获取智能回复。
方案
了解下GPT的接口能力
首先,回归题目,我们要利用ChatGPT(或OpenAI的gpt接口)做一个智能客服,但你会发现ChatGPT可能根本不了解你公司的业务场景,你问它问题它有时候懂一点,有时候不懂,更可怕的是经常对不懂的东西胡说八道。那么我们有什么办法做一个不会胡说八道的智能客服呢?
先说说ChatGPT为什么容易胡说八道?因为它是一个预训练的生成式大模型,原理是通过学习大量的知识(数据),以概率最大化的方式输出文本。知识(数据)虽然来自互联网公开数据和一些合作厂商,但它的知识(数据)是来自2021年9月份之前的,而且因为学习的数据量巨大,当你的公司业务在互联网的曝光度还没那么高的时候,在它学习的权重里也会降低,导致了你问它跟你业务相关的问题,它也不是完全不知道,所以根据预测概率的方式,给你吐了一些胡说八道的回答。
因为没有其他相关知识,这个在机器学习领域叫Zero-Shot(零样本分类或零样本学习),一般对于通识类的问答会好一些。一些推理类的,在零样本学习的情况下,也会比较差,所以一般推理类可以通过提示语让它分步分析(step by step),中间产生的过程信息,反过来可以反哺它的推理,最终能提高推导质量。
所以在智能客服这个场景,我们应该使用它更擅长的Few-Shot能力,即小样本分类(或小样本学习)。我们在问它问题的时候,提前把一些相关的知识点告诉它,它就能从你的知识点里,总结和学习到信息,最后输出一个比较靠谱的问答结果
例如:在zero-shot的情况下,问它
YCloud有什么服务
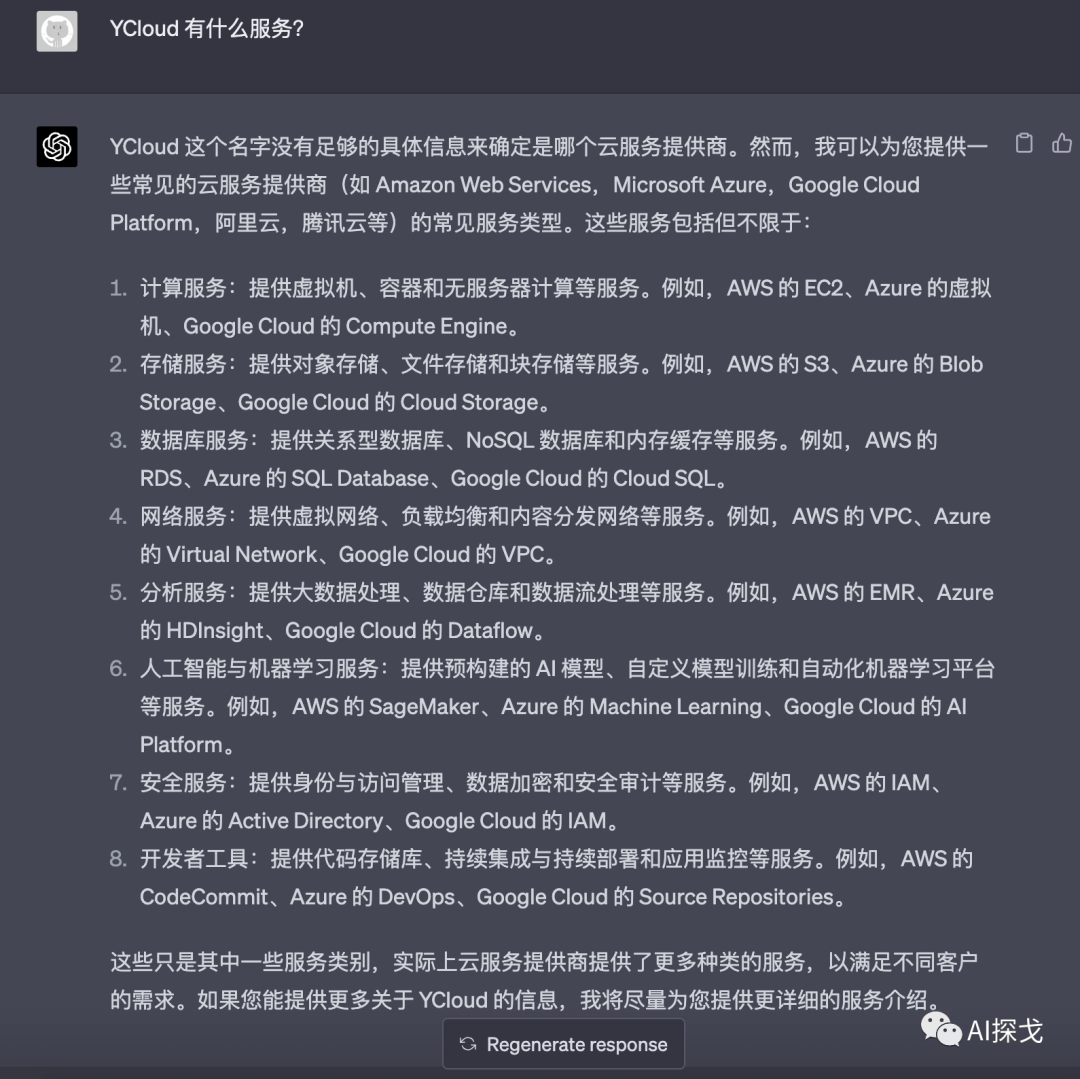
很明显,它的知识里面,对YCloud是不了解的,但它通过Cloud这个关键字,推断YCloud可能是跟其他云厂商一样的。
然后我就给它一点样本参考:
YCloud是一家提供CPaaS服务的公司,他有哪些服务?
它回答
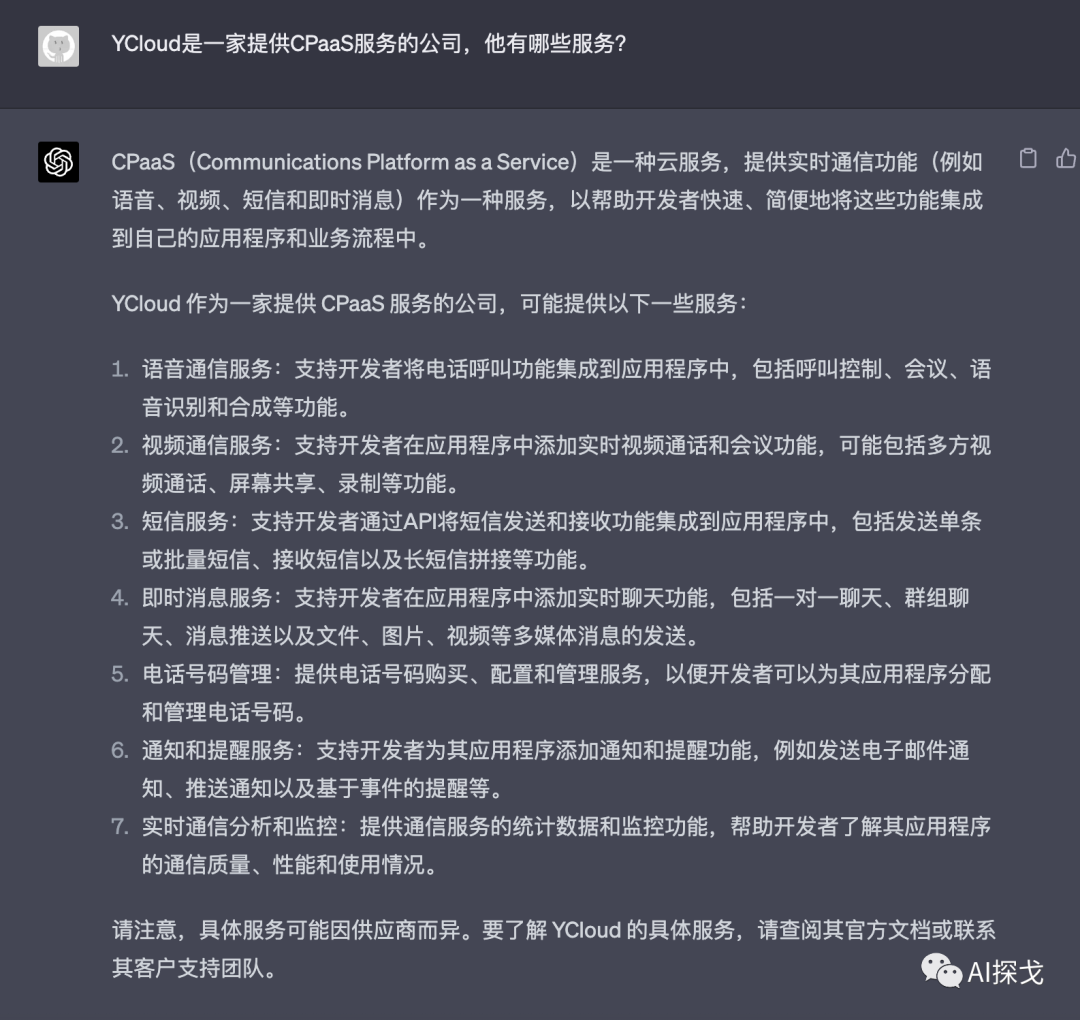
也很明显,它掌握的知识里包含CPaaS这个术语,而且知道CPaaS是干啥的,所以通过CPaaS猜测了YCloud大约有这些服务,虽然准确了一些,但依然不够格作为YCloud的客服代表,因为我们给它的知识点信息量太小了。
解决方案
所以解决它胡说八道的方案就呼之欲出了——提前告诉它YCloud的业务知识点,再让它体用强大的Few-Shot能力,根据我们提供的知识点回答问题
prompt:
你是一个YCloud智能客服,请根据下面的知识点回答问题。
知识点:"""
<一些业务知识>
"""
问题:<知识点相关问题>
那么这时又有新问题来了,很多公司的业务知识点不少,很容易就触及了gpt的接口限制(例如gpt-3.5-turbo模型,每次请求的max_tokens 是4096,大约就是3000多个单词,而且这个max_tokens 是包含请求的内容的token数和输出的内容的token数。gpt4有8k和32k的token数,但他的单价比gpt-3.5贵几十倍)。每次问它前,都把公司所有的业务知识告诉它(比如YCloud的产品介绍文档:https://docs.ycloud.com/docs,足足有几万字,幸好是写得足够细粒度),显然不太可行,那有其他方案吗?
YCloud产品介绍文档
通过语义查找相关内容
传统使用分词+关键字+Query重写实现模糊搜索的方案,虽然也能匹配到一些相关的内容,但远不如通过语义匹配的方式,找到跟用户语义更相关的内容。OpenAI提供相关的能力,叫 embeddings。embeddings的接口功能上就是输入一串文本,返回一个长度为1538的向量(vector,类似数组,但有维度属性,每个元素不能和其他元素更换位置)。这个向量就是代表了输入的文本通过GPT的模型抽取出来的语义特征。这个特征有1538个维度,如果有两个特征相近的文本,基本可以断定它们之间关联性是比较强的。
那么有什么东西可以判断两个或者多个文本的特征相似度呢?简单地,可以通过求余弦相似度(cosine similarity)的方式,对比两组向量的余弦相似度值(最大为1,最小0),值越大代表两个向量越接近(类似于三角函数里用cosθ衡量两条线的夹角一样)。当然也有成熟的向量数据库产品、中间件,适用于对比数据规模较大的向量之间的特征。有了这个接口能力之后,我们只需要把产品文档进行拆分到小颗粒度,尽量让每个产品的介绍文字tokens数不超过3000个token,另外预留1000左右个token给客户输入和AI进行输出(注意这是为openai的gpt3.5模型适配的,如果其他的LLM可以提供更多的token能力,可以适当放宽限制)。然后把这些产品介绍变成一个个的知识点,形成知识向量库。用户输入查询内容之后,我们先通过embeddings把用户输入的内容抽取特征,再跟知识库向量库进行对比排序,找出语义最接近的产品介绍,作为Few-Shot 的知识点,传递给GPT,GPT根据这些知识点回答用户的问题基本就靠谱了。在向量比对的过程中,可以根据自己公司的业务情况,调整向量相似度的阈值,如果最接近的知识库仍然低于这个阈值(比如0.7、0.8,根据业务实际调整),此时可以留一个勾子(hook),告诉用户该问题无法回答(或者把回答转交给真人客服),从而不会胡说八道。
方案小结
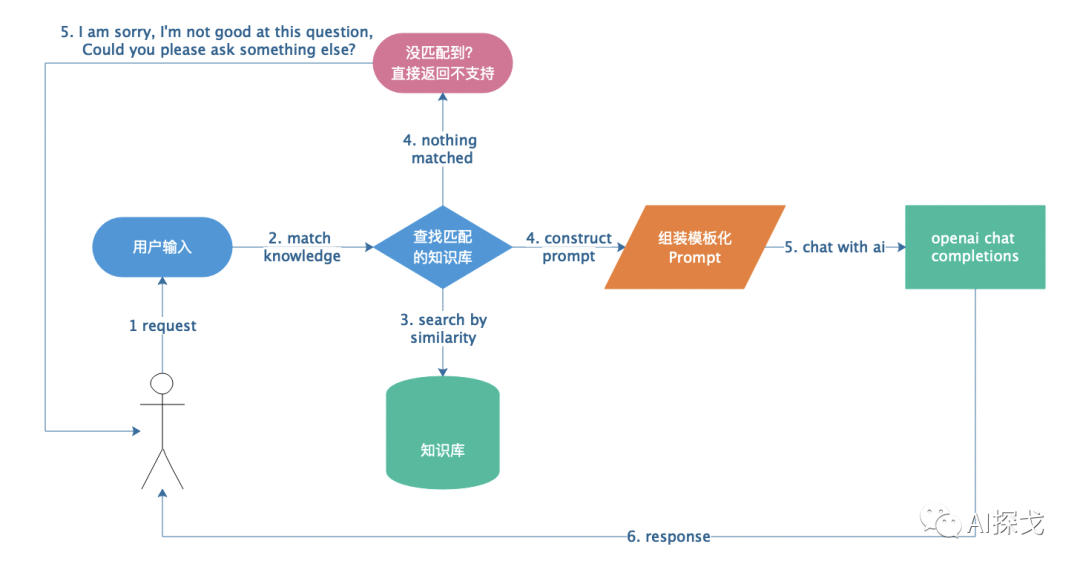
以上就是做一个不会乱说话,且懂你业务的智能客服的总体方案,我们总结一下:
1.整理知识库,将每个知识块大小控制在OpenAI接口的限制范围内(不排除其他LLM可以更大的token),然后形成知识向量库
2.对用户的输入进行向量化特征抽取,之后对比查找最接近的知识向量库
3.将匹配到的知识和问题,组装成提示语(prompt),使用OpenAI的chat/completions接口进行智能问答
其他方案?
另一个让OpenAI懂你的业务的方案,是用微调(fine-tune),但我目前不推荐。
因为OpenAI训练出的1750亿参数的大模型,是因为它阅读了大几千亿的token,才沉淀出来的模型(知识),相当于在一个大规模的参数模型上,通过微调的方式让它改动一些参数以适应你的业务形态。那么可以想见,你需要微调的token数应该不少,因为它原来被洗脑了很多其他知识,需要再反复给它洗脑洗成懂你的业务知识。
此外目前OpenAI开放支持的微调模型,只有早期的ada、babbage、curie、davinci,这些模型的能力远远弱于gpt 3.5和gpt4,相当于你在一个弱很多的模型上做微调,除了成本高,效果还比较差。
所以目前阶段我是不建议用微调的,也许未来OpenAI开放了3.5甚至4的微调能力之后,可以再试试看。其他的LLM也有支持微调的,在成本可控,质量性能好的情况下,微调是一个不错的方案,而且是一个终极方案——每个企业可以拥有自己的业务大模型(成本可以接受的话)。
用YCloud打通WhatsApp
接下来,我们把这个客服,通过YCloud打通WhatsApp Business API,就变成一个可以对客户提供问答功能的WhatsApp智能客服了。总共就这么几步:
1. 首先注册YCloud账户;
2. 创建WhatsApp账户,连接到WhatsApp的手机号码(需要一些企业认证过程以及号码的验证过程);
3. 进入YCloud Inbox平台,创建一个WhatsApp 收件箱,该收件箱连接第2步创建的WhatsApp账户;
4. 创建AgentBot机器人(请联系YCloud商务,可以优先开通功能)和实现上面应答的业务逻辑;
5. 反复更新调整知识库,让AI回答更精准。
最后看一下效果
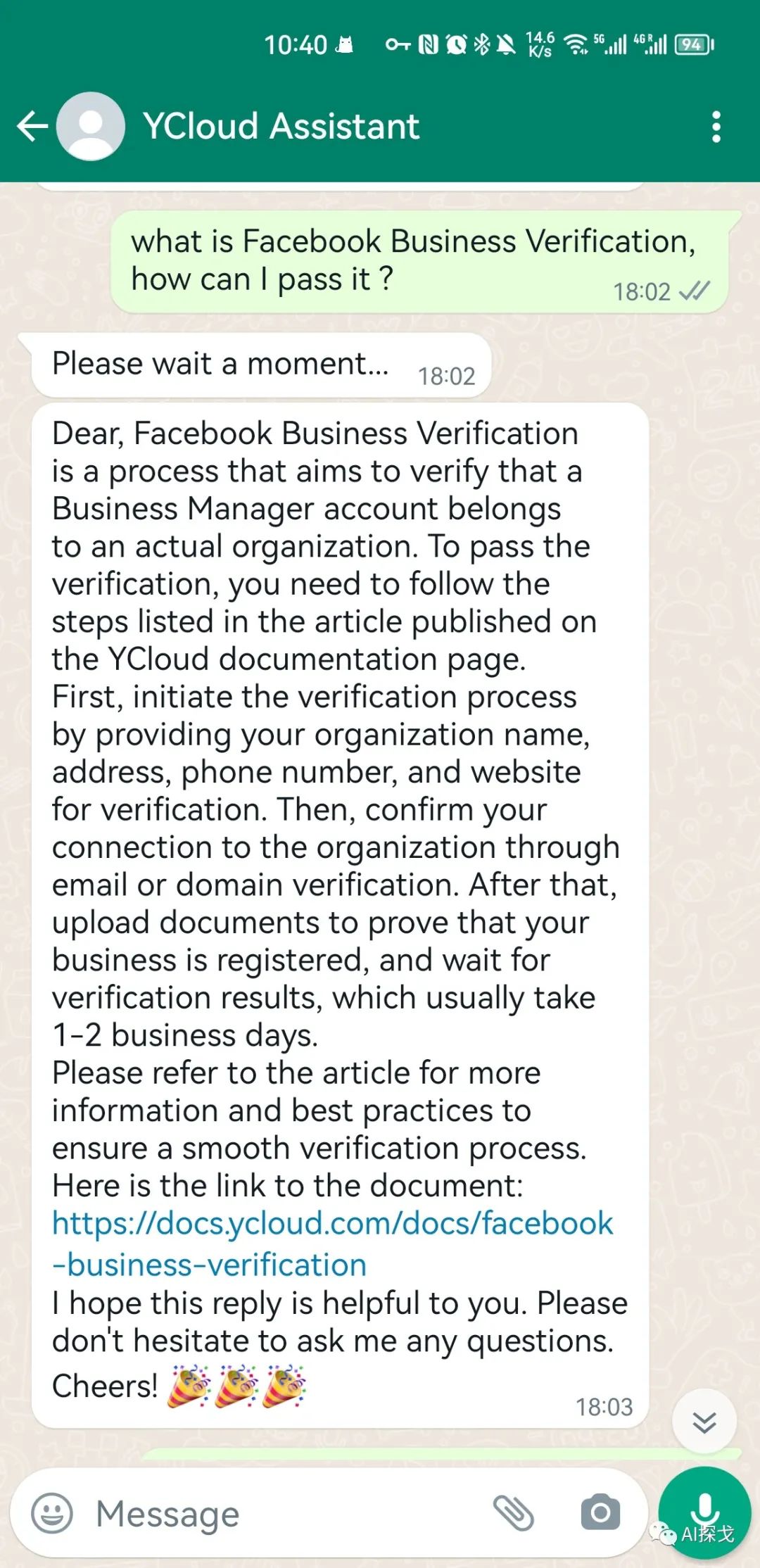
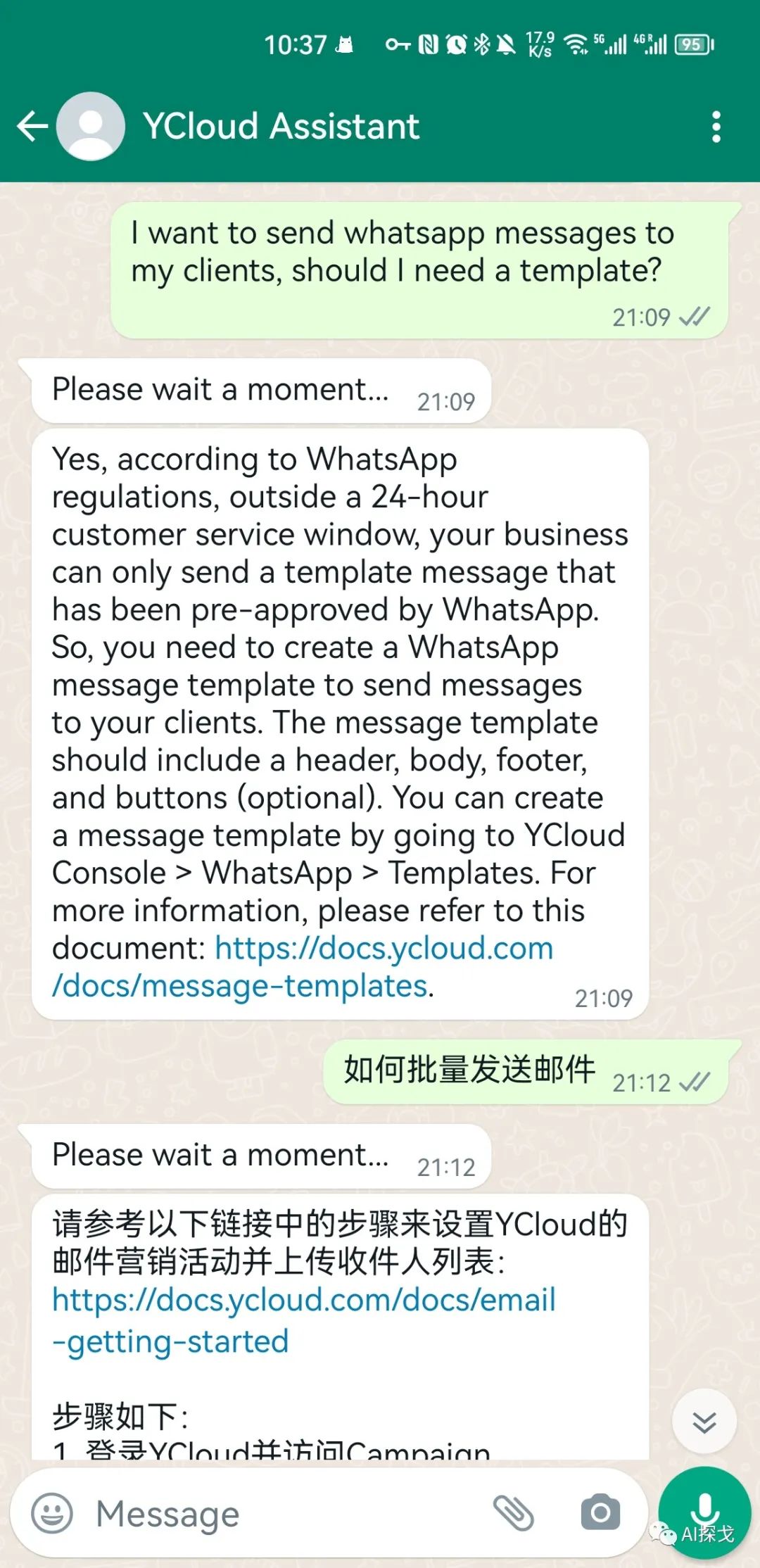
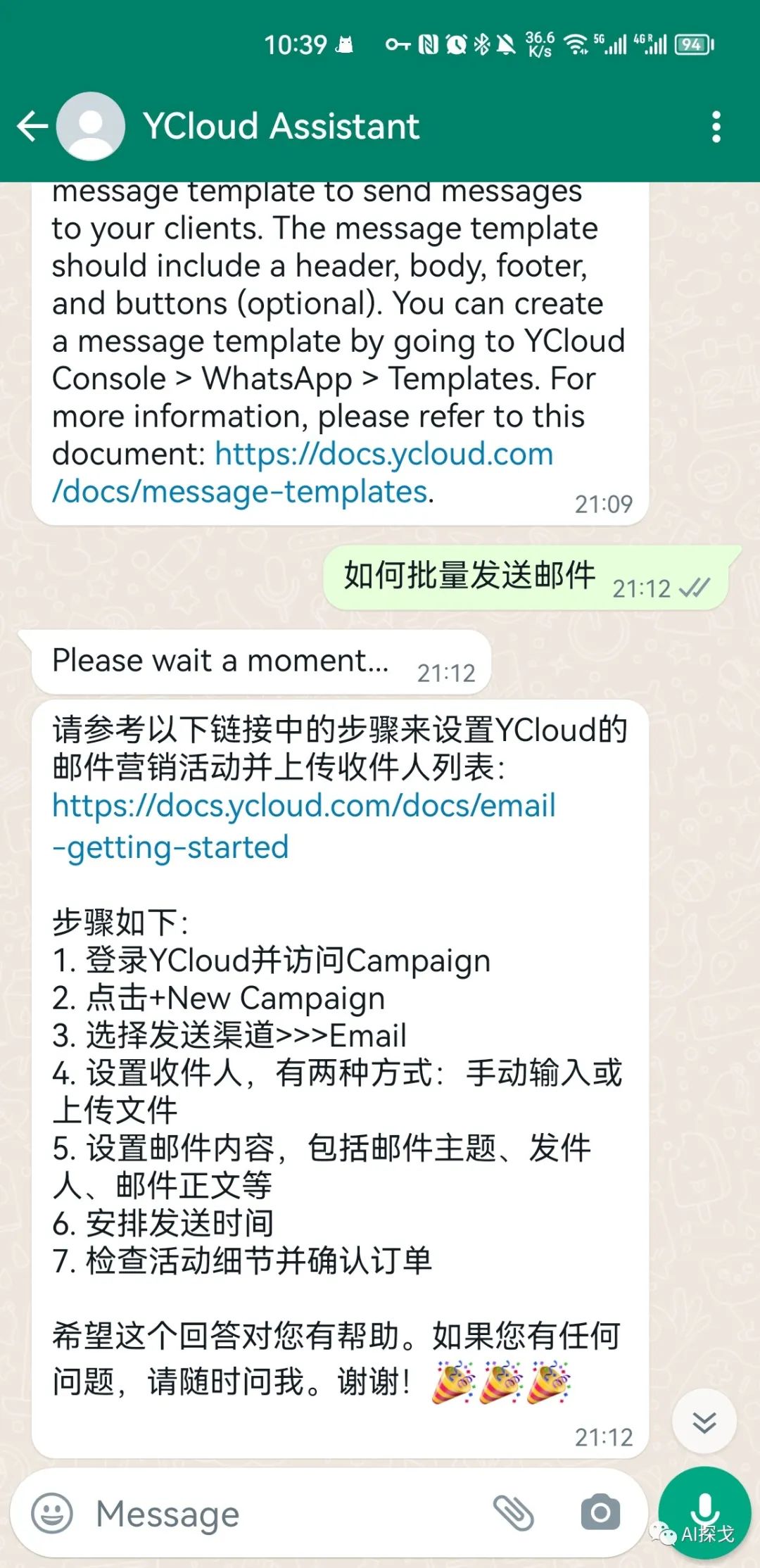
可以看出,基本是参考相关的知识点来回答的,非常靠谱。这里有一个有意思的点,当用户用英文提问时,AI用英文回答,当用户用中文提问时,AI用中文回答。这对ChatGPT来说并不难,但我的知识库内容其实是全英文的,并没有中文在里面,难道OpenAI的embeddings能力这么强,可以全语言匹配吗?并不是,是因为我在实现这个bot的实际上做了一些Trick:
1. 归一化
所谓归一化就是把所有输入都转化为相同的衡量尺度,再进行对比。比如,在国内短信审核的时候,有些短信内容是这样的:"亲爱的+5扣扣幺幺⑤巴巴①三你好。。。",对于这种文案,我们人类的大脑会自动将其归一化为"亲爱的加我QQ1158813你好。。。",并果断将其驳回。而具体到我们智能客服这个例子,由于我们的知识库都是英文,所以我们需要把用户的输入也统一翻译成英文(没错,翻译也可以用gpt来做,不同的只是提示语),再用embeddings进行向量对比。拿到知识库之后,用户输入的问题原封不动传给gpt,它就会按照用户提问的语言来进行回答。
2. 模板化输出
如果想让AI输出的内容显得更专业(更有温度)一些,可以把专业(有温度)的文案模板作为提示语的一部分告诉它,让它按模板输出。
prompt:
你是一个YCloud智能客服,请根据下面的知识点回答问题:
知识点:"""
<一些业务知识>
"""
问题:<知识点相关问题>
回答模板:"""
亲爱的,你好
{{你的回答}}
希望我的回复可以帮到您,祝您一切顺利~
"""
<内容> 为需要提前准备的内容
{{你的回答}} 为prompt的一种模板写法,让AI能关注到他的内容应该怎么放置。
3. 温度调节
Chat Completions接口中有一个temperature参数是用来控制模型输出的内容的个性化程度的。取值是0-1(注意有些接口是0-1,有些是0-2,但作用是类似的),越小代表输出的内容越精准,越大代表内容越个性(花里胡哨)。具体到智能客服这个场景,我希望它不要油嘴滑舌,所以我设置为0,更精确的回答(注意依然无法100%精确)。
结语
好了,介绍了这么多,是不是发现实现一个智能客服挺容易的?
其实这些功能都在OpenAI官方的cookbook里有介绍,特别embeddings的能力,绝对是容易被只跟它在线聊天的人忽视的非常牛X的能力。像很多的基于文档的问答、语义化搜索,也都是基于这个方案来做的。
用YCloud实现WhatsApp客服有两种路径,一种是自己通过YCloud提供的WhatsApp Business Platform API + YCloud相应的webhook推送,在webhook server里面实现问答逻辑。另一种是通过YCloud已有的Inbox平台,创建Agentbot(需要联系YCloud的商务,提供你的应用场景,由于目前火爆,需要排队审核)来实现。通过Inbox实现的好处是,有一个专业的客服平台,真人客服可以上去直接看机器人和用户聊天的情况,审查AI的回复术语,对于回答不好(真无法100%保证不会说错)的地方,及时进行调整,问答逻辑上遇到不懂的问题(比如匹配不到关联性较强的知识库)也可以切换成人工接管回复,这样可以给终端用户更好的用户体验。
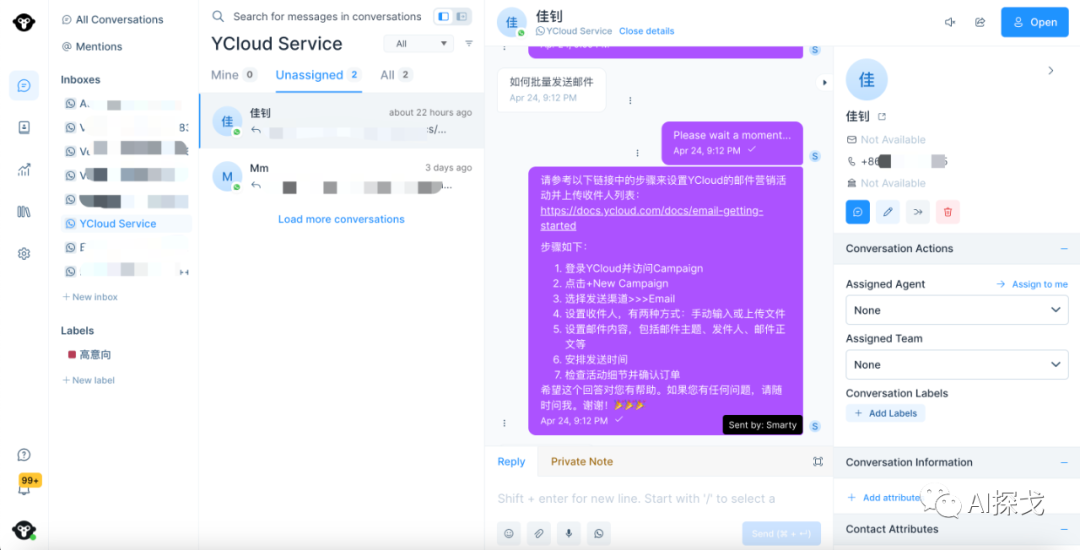
用YCloud Inbox对接客服坐席
智能客服不仅限于做搜索,其实售前的跟单话术,只要提炼出知识点,也可以用智能客服来做的。甚至可以借鉴上面的实现逻辑,做一个在线的商品推荐机器人(因为商品信息大多数情况下是公开可见的)。
风险提示
最后做一下风险提示:由于OpenAI是一家私人公司,我上面传递的数据都是公开网页上的知识点,不涉及到任何用户、公司、国家的敏感数据,所以可以放心调用。大家在实现类似的业务时,也请考虑自身的数据是否敏感,特别是涉及到个人、公司、国家的敏感信息,一定要做好管控,遵守业务所在国家的法律法规,防止造成不必要的损失或者法律风险。
后话
在实现上述的WhatsApp智能客服过程中,我全程都是跟GPT4结对编程的,主要的代码实现逻辑都是GPT4写的,我更多是提出问题和一些不合理的点(比如一些不熟悉的web接口定义,提bug等),让GPT4持续改进代码。这里开个坑,后面再补一篇如何与GPT4进行结对编程,敬请期待~~
参考资料:
1. OpenAI官方cookbook: https://github.com/openai/openai-cookbook
2. YCloud官网: https://www.ycloud.com/ 或 点击阅读原文
3. 如何提高zero-shot时的推理能力:Let's think step by step:https://arxiv.org/abs/2205.11916
4. 一些支持向量搜索的数据库:redis、pinecone、milvus、zilliz等等
注:本文授权转载于公众号:AI探戈。

